
TechBerlin posted a short video about last weekend’s People in Beta Festival at betahaus.
Science and scientific research
TechBerlin posted a short video about last weekend’s People in Beta Festival at betahaus.
This Saturday, 1st October Betahaus Berlin held their People in Beta Festival.
During the event we could enjoy unusually warm October weather.
Berlin on a lovely autumn day:




Makerplatz a.k.a. Moritzplatz:

Now let’s start at the betahaus:

Beatriz of cinematografa.com filming during the event:

Awesome foundation pitch during betabreakfast:

Awesome foundation winner Willempje from Figure Running:

Ali from Protonet explaining their social network software and hardware box:

Lorenz from EyeEm explaining their photo sharing service and giving a flash course on the history of photography:

Alex Ljung from SoundCloud sharing about starting your own company:


You can hear his session recorded here – of course uploaded to SoundCloud. The recording is not ideal as I had the level on manual but had to fish out some headphones from my cramped backpack, sorry:
[soundcloud params=”auto_play=false&show_comments=true”]http://soundcloud.com/toha-2/alex-at-people-in-beta-2011[/soundcloud]
After the sessions and work shops some more pitches during betapitch.
Doonited social enterprise pitch:

5 minutes for pitching the idea – then 5 more for Q&A session:

Thorsten from Musicplayr explaining his business:

In the end winning the betapitch:
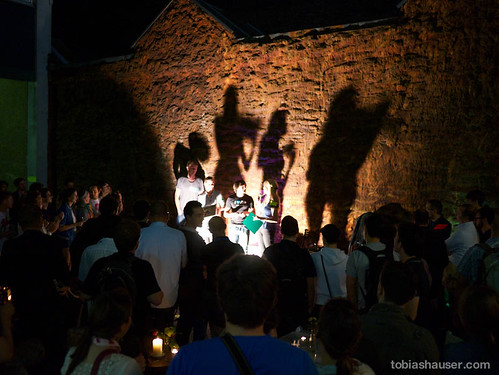
Betajamming after work:

Betahaus’ own Christoph joining in:



The Department of Business Administration at the University of Rostock will be hosting their 2nd Rostock Conference on Service Research.
The conference will be held in Rostock between September 23 and 24, 2010. Further information is available at the Rostock Conference on Service Research website.

On September 2nd and 3rd the closing conference of the project BMInno will be held in Rostock.
The topic will be: Success through innovation – managing corporate change.
More information can be found on the project’s website: BMInno website
Ergänzende Unterlagen zu den Vorlesungen
2: Personalplanung und
5: Arbeitsstrukturierung
der Veranstaltung Betriebliches Personalwesen der TAW, Studienzentrum Rostock, Frühjahr 2010.

Photo of the Library of Adams House in Harvard by Paul Lowry
The annual renewal for Harvard Business Review this year offers a special collection of articles on leadership as an additional incentive.
For those who did not get the offer the good news is that the articles can be bought separately from the HBR website.
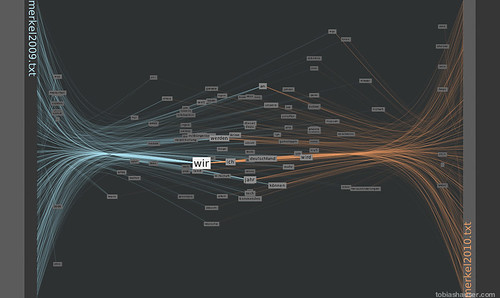
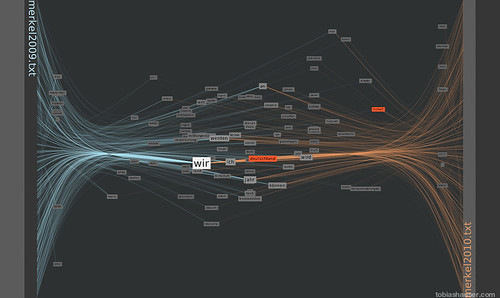
To show an example in a language other than English for the FacingWords processing sketch I used it to compare the 2009 new year’s speech from German Federal Chancellor Angela Merkel to her 2010 speech.
The vertical position of the words shows their weighted occurrence relative to the beginning (top) and end (bottom) of the texts.
The horizontal position shows the relative word weight between the texts. That is the number of occurrences in the left text as opposed to the number in the right text.
Words that appear at either left or right margin are used exclusively in the respective text.
Words horizontal positioned in the middle are (more or less) equally used in both texts.
In the first picture one can see a concentration of words in the middle. From this it appears that both texts are using a relatively high proportion of shared words. This could mean that both texts are centered on similar concepts.
Pressing ‘s’ in the sketch switches to scratch mode where only the word representations close to the mouse pointer are shown.
The central cluster is highlighted in the following image by this way:

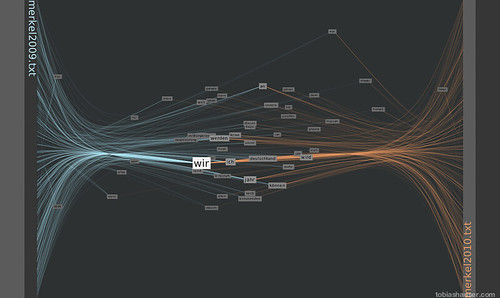
Using the number keys 1-9 will only render the 10-90% most often used words. Pressing ‘0’ will show all words again.
This image shows only the top 50% of words used in both texts:
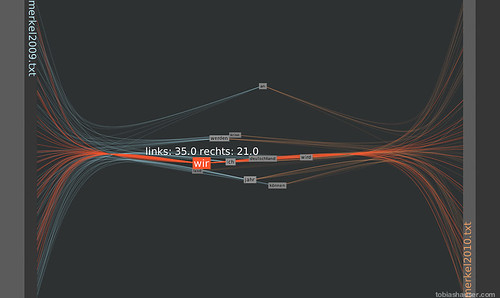
Further reducing the detail to the 10% most used words shows that both ‘we’ (=’wir’) and ‘I’ (=’ich’) are among the most commonly used words.
Hovering over a word with the mouse will highlight the word and its connections to the anchor positions in the texts (red in this case). At the same time the number of the word’s occurrences in both texts are displayed. The word ‘ich’ (=’I’) is used 11 times in the left text and 9 times in the right text for a total of 20 times.

In comparison the word ‘wir’ (=’we’) is used 35 times in the left text and 21 times in the right text, 56 times in total.
This shows that ‘we’ is preferred over ‘I’ in both speeches.
The sketch processes the input texts against a stop list of words to be filtered out. This is done to weed out articles, commonly used pronouns or words that are to be excluded from the text analysis. In this case for my casual analysis ‘we’ and ‘I’ were not in the stop list to have a look at how they are used. For another analysis this could be changed.

Clicking on one or more words toggles them to be highlighted. Pressing ‘a’ for analysis mode reduces the display to the highlighted words.

Mousing over the word anchors in the left and right margin areas displays the context of the word at this anchor point.
Pressing ‘+’ or ‘-‘ increases or decreases the amount of context shown to make it easier to study the context in which the word is used.

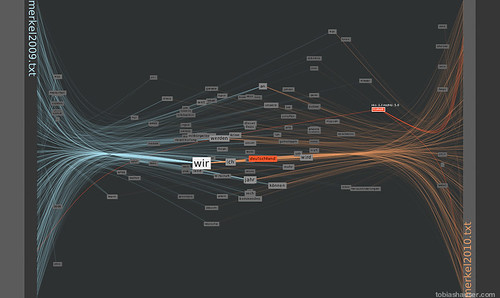
in this example the usage of the words ‘Deutschland’ (=’Germany’) and ‘Freiheit’ (=’Freedom’) is analyzed. From this short analysis it appears that the term ‘Freiheit’ is used in conjunction with the German reunion in the year 1990.
Pressing ‘a’ again will return to the previous display with the 10-100% most often used words shown, depending on the previous setting.
Pressing ‘r’ at any time resets the display to normal mode with all words shown (100%) and no words highlighted.
The images were made using the respective Processing method to save a PNG file. In the sketch this is done pressing ‘i’ at any time.
In addition a movie of the on-screen action can be taken pressing the ‘m’ key which will toggle movie mode on and off.

The Department of Business Administration at the University of Rostock issued a Call for Papers for their 2nd Rostock Conference on Service Research. Interested parties and individuals can submit their contribution either as a full paper or an extended abstract (500 words max.), either in English or German before March 1, 2010.
The conference will be held in Rostock between September 23 and 24, 2010. Further information is available at the Rostock Conference on Service Research website.

About 2 weeks ago I came across Jeff Clark‘s post Two Sides of the Same Story. He shows both his and Jer Thorpe‘s visualisations of comparing two texts.
The work of both of them really intrigues me. Jer plans to release the tool as well as the code in the nearer future. I am looking into the visualisation of qualitative and verbal/textual data for my diss. where I will need to analyse interview data early mext year. While I plan to use the known QDA tools for my work the text comparison shown by Jer and Jeff seem to be really useful.
The fascination went so far that I copied Jer‘s effort this weekend in Processing. The deciding bit was that the book „Visualizing Data“ by Ben Fry (who made processing) arrived as a interlending library loan for me on friday. Ben gives some well explained and documented examples plus you can download the code from his website. You can use the search inside at the Visualizing Data (Amazon affiliate link) product page to look at the TOC and Index.
It has been an awful long time ago that I wrote a piece of code. Long enough to be a procedural spaghetti coder. To make it easier I tried to keep the presentation as close to the antetype as possible. I hope Jer doesn‘t mind and takes being copied as the compliment it is.
I filter both texts to be compared through a list of primitive words that will be excluded for the analysis. The words displayed can be controlled with the number keys 0 through 9 to filter only the x% most frequently used words.
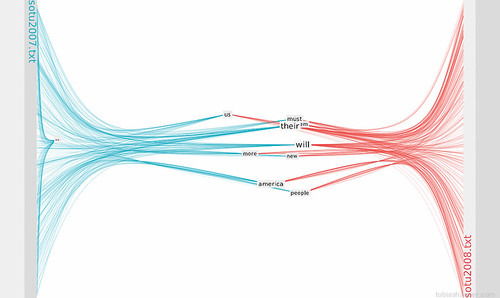
Here you can see the display restricted to the 10% most used words:
This image shows the top 40% most used words:
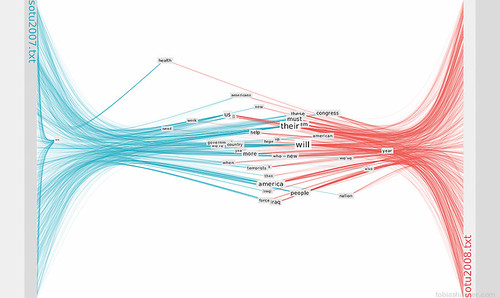
Mousing over a word will highlight the word and all its connections. One or more words can be marked (by clicking) to be isolated. In analysis mode mousing over the text anchors shows the word‘s context.
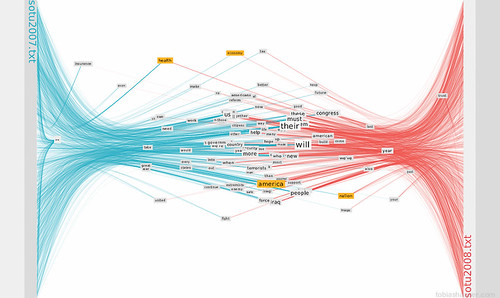
This is how the analysis mode looks:
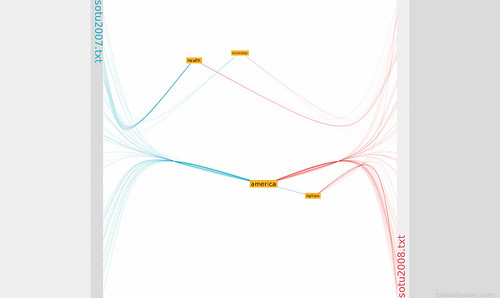
I called the sketch Facing Words in memoriam of the old Unreal Tournament map Facing Worlds.