
About 2 weeks ago I came across Jeff Clark‘s post Two Sides of the Same Story. He shows both his and Jer Thorpe‘s visualisations of comparing two texts.
The work of both of them really intrigues me. Jer plans to release the tool as well as the code in the nearer future. I am looking into the visualisation of qualitative and verbal/textual data for my diss. where I will need to analyse interview data early mext year. While I plan to use the known QDA tools for my work the text comparison shown by Jer and Jeff seem to be really useful.
The fascination went so far that I copied Jer‘s effort this weekend in Processing. The deciding bit was that the book „Visualizing Data“ by Ben Fry (who made processing) arrived as a interlending library loan for me on friday. Ben gives some well explained and documented examples plus you can download the code from his website. You can use the search inside at the Visualizing Data (Amazon affiliate link) product page to look at the TOC and Index.
It has been an awful long time ago that I wrote a piece of code. Long enough to be a procedural spaghetti coder. To make it easier I tried to keep the presentation as close to the antetype as possible. I hope Jer doesn‘t mind and takes being copied as the compliment it is.
I filter both texts to be compared through a list of primitive words that will be excluded for the analysis. The words displayed can be controlled with the number keys 0 through 9 to filter only the x% most frequently used words.
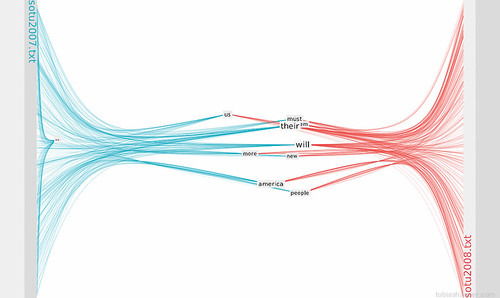
Here you can see the display restricted to the 10% most used words:
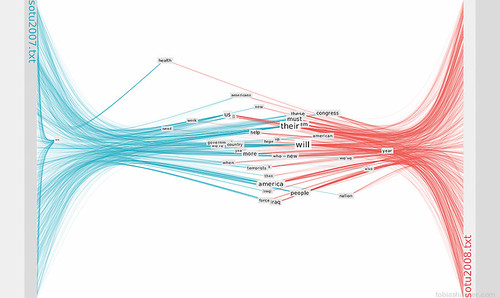
This image shows the top 40% most used words:
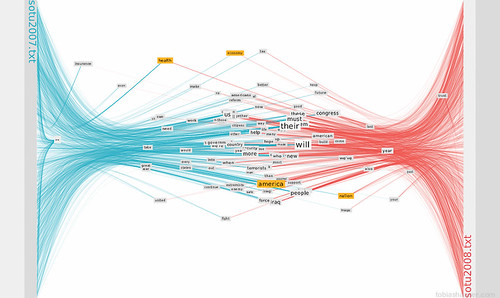
Mousing over a word will highlight the word and all its connections. One or more words can be marked (by clicking) to be isolated. In analysis mode mousing over the text anchors shows the word‘s context.
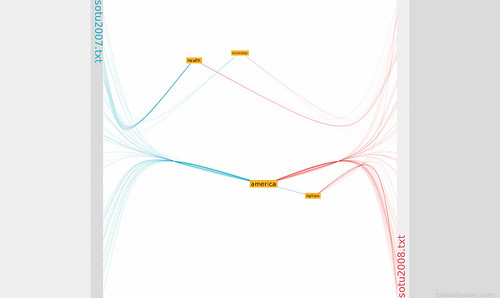
This is how the analysis mode looks:
I called the sketch Facing Words in memoriam of the old Unreal Tournament map Facing Worlds.
2 replies on “Facing Words”
[…] show an example in a language other than English for the FacingWords processing sketch I used it to compare the 2009 new year’s speech from German Federal […]
Do you have the code online, or as a working applet? Would love to play around with it.