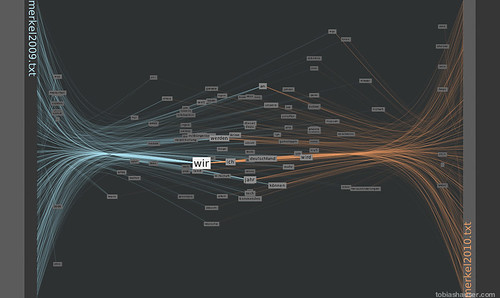
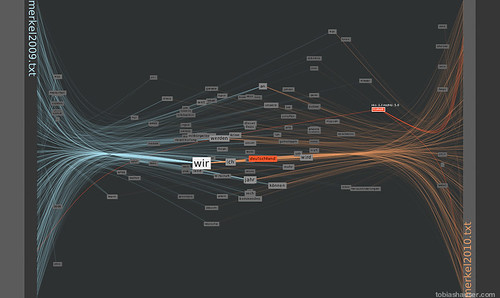
To show an example in a language other than English for the FacingWords processing sketch I used it to compare the 2009 new year’s speech from German Federal Chancellor Angela Merkel to her 2010 speech.
The vertical position of the words shows their weighted occurrence relative to the beginning (top) and end (bottom) of the texts.
The horizontal position shows the relative word weight between the texts. That is the number of occurrences in the left text as opposed to the number in the right text.
Words that appear at either left or right margin are used exclusively in the respective text.
Words horizontal positioned in the middle are (more or less) equally used in both texts.
In the first picture one can see a concentration of words in the middle. From this it appears that both texts are using a relatively high proportion of shared words. This could mean that both texts are centered on similar concepts.
Pressing ‘s’ in the sketch switches to scratch mode where only the word representations close to the mouse pointer are shown.
The central cluster is highlighted in the following image by this way:

Using the number keys 1-9 will only render the 10-90% most often used words. Pressing ‘0’ will show all words again.
This image shows only the top 50% of words used in both texts:
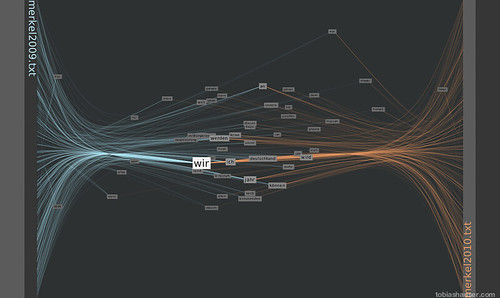
Further reducing the detail to the 10% most used words shows that both ‘we’ (=’wir’) and ‘I’ (=’ich’) are among the most commonly used words.
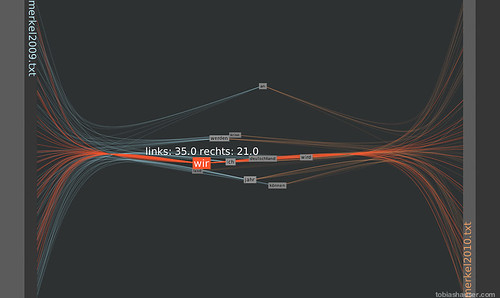
Hovering over a word with the mouse will highlight the word and its connections to the anchor positions in the texts (red in this case). At the same time the number of the word’s occurrences in both texts are displayed. The word ‘ich’ (=’I’) is used 11 times in the left text and 9 times in the right text for a total of 20 times.

In comparison the word ‘wir’ (=’we’) is used 35 times in the left text and 21 times in the right text, 56 times in total.
This shows that ‘we’ is preferred over ‘I’ in both speeches.
The sketch processes the input texts against a stop list of words to be filtered out. This is done to weed out articles, commonly used pronouns or words that are to be excluded from the text analysis. In this case for my casual analysis ‘we’ and ‘I’ were not in the stop list to have a look at how they are used. For another analysis this could be changed.

Clicking on one or more words toggles them to be highlighted. Pressing ‘a’ for analysis mode reduces the display to the highlighted words.

Mousing over the word anchors in the left and right margin areas displays the context of the word at this anchor point.
Pressing ‘+’ or ‘-‘ increases or decreases the amount of context shown to make it easier to study the context in which the word is used.

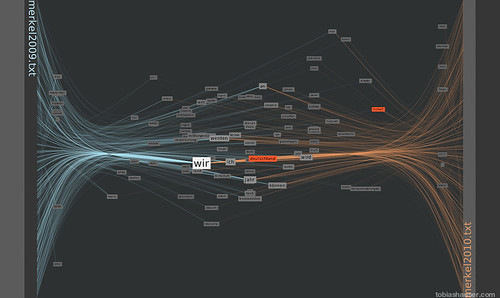
in this example the usage of the words ‘Deutschland’ (=’Germany’) and ‘Freiheit’ (=’Freedom’) is analyzed. From this short analysis it appears that the term ‘Freiheit’ is used in conjunction with the German reunion in the year 1990.
Pressing ‘a’ again will return to the previous display with the 10-100% most often used words shown, depending on the previous setting.
Pressing ‘r’ at any time resets the display to normal mode with all words shown (100%) and no words highlighted.
The images were made using the respective Processing method to save a PNG file. In the sketch this is done pressing ‘i’ at any time.
In addition a movie of the on-screen action can be taken pressing the ‘m’ key which will toggle movie mode on and off.



